
AI Powered PDF Summarizer Using Python

Introduction:
AI-Powered PDF Summarizer is a tool that extracts and summarizes research papers from ArXiv PDFs using Ollama (Gemma 3 LLM). The system provides structured, downloadable summaries to help researchers and professionals quickly grasp key findings.
Reading long documents—such as reports, research papers, or books in PDF form—can be quite time-consuming and demanding. Many people, including researchers, office workers, teachers, and students, must routinely peruse a lot of these materials. But reading every word takes much time. Here is where the PDF Summarizer finds application.
Designed with Python programming language, the PDF Summarizer is a tool. Its primary purpose is to quickly produce a brief synopsis from a PDF file indicating the most crucial points from the document. Without reading everything, this saves time and clarifies the major concepts for people.
What Does the PDF Summarizer Do?
This tool has one simple goal: To help people to understand big documents quickly by giving a short summary.
Here is what it can do:
- It can Read PDF files and pull out the text inside.
- It can Understand the meaning of the text using smart language tools.
- It can Make a short summary that keeps the most important points.
- Let the user read, copy, or download the summary.
How Does It Work?
Here’s a simple step-by-step look at how the tool works:
- Upload the PDF: The user chooses a PDF file to upload.
- Get the Text: This tool reads all the text inside the PDF using special Python libraries like PyMuPDF or pdfminer.six.
- Clean the Text: It will removes unnecessary symbols, numbers, or pages, and splits the text into smaller parts (like sentences).
- Summarize: Then It uses the smart computer programs (called NLP models) to find the most important parts of the text and put them together in a short version. It can either:
- Pick important sentences (extractive summary), or
- Write a new, shorter version (summary).
- Show the Result: The final summary is shown on the screen, and users can copy or save it.
Required Modules Or Packages:
- FastAPI – It is a modern and fast web framework for building APIs by using Python 3.7+ .
- Uvicorn – It is a lightning-fast ASGI server, which is used to run FastAPI and other asynchronous Python web apps.
- Requests – It is a simple and elegant HTTP library, which is used in making API calls and handling web requests.
- LangChain – It is a framework to build applications using large language models (LLMs) with tools and memory.
- Pydantic – It is a data validation and parsing library which is using Python type annotations.
- PyMuPDF – A library for reading, editing, and extracting text or images from PDF and other document types.
- Streamlit – It is a fast way to build and share data apps using Python.
- Ollama – A tool to run and manage large language models (LLMs) locally on your machine.
- HTTPX – It is An HTTP client for Python with async support .
To install these Packages, use the following steps:
- Make a .txt file and type in the names of all modules or packages which is given above .
- Now, open CMD and type the following command:
pip install -r requirements.txt
- To Install Ollama and Gemma 3 LLM
- Install Ollama – MacOS/Linux:
curl -fsSL https://ollama.com/install.sh | sh
- Download Gemma 3 Model
ollama pull gemma3:27b
How To Run The Code :-
Method 1 :-
Step 1 . First , You Download and Install Visual Studio Code or VS Code In your PC or Laptop by VS Code Official Website .
Step 2 . Now Open CMD As Administrator and install the above packages using Pip .
Step 3 . Now Open Visual Studio Code .
Step 4. Now Make The files named as main.py and frontend.py.
Step 5 . Now Copy And Paste The Code from the Link Given Below ⬇️
Step 6 . After pasting The Code , Save This & Click On Run Button .
Step 7 . Now You will See The Output .
Method 2 :-
Step 1 . First , You Download and Install Visual Studio Code or VS Code In your PC or Laptop by VS Code Official Website .
Step 2 . Now Open CMD As Administrator and install the above packages using Pip .
Step 3 . Now Open the link , which is provided below.
Step 4. Now download the ZIP file of the code.
Step 5 . Now Extract the ZIP file and Open in VS Code.
Step 6 . Now go to the main file and click on run button.
Step 7 . Now You will See The Output .
Code Explanation:
This Python code is used to Create a System, through which we can Summarize any Long PDF Documents. Ensures that You Have Downloaded the modules given above .\
1. Imports:
import os
import logging
import requests
import fitz
import asyncio
import json
import httpx
from concurrent.futures import ThreadPoolExecutor
from fastapi import FastAPI
from pydantic import BaseModel
from langchain.text_splitter import RecursiveCharacterTextSplitter
import ollama
import streamlit as st
import requests
import time
- FastAPI – It is a modern and fast web framework for building APIs by using Python 3.7+ .
- Uvicorn – It is a lightning-fast ASGI server, which is used to run FastAPI and other asynchronous Python web apps.
- Requests – It is a simple and elegant HTTP library, which is used in making API calls and handling web requests.
- LangChain – It is a framework to build applications using large language models (LLMs) with tools and memory.
- Pydantic – It is a data validation and parsing library which is using Python type annotations.
- PyMuPDF – A library for reading, editing, and extracting text or images from PDF and other document types.
- Streamlit – It is a fast way to build and share data apps using Python.
- Ollama – A tool to run and manage large language models (LLMs) locally on your machine.
- HTTPX – It is An HTTP client for Python with async support .
2. FastAPI Setup:
app = FastAPI()
class URLRequest(BaseModel):
url: str
A FastAPI app is initialized.
URLRequest defines the request model with a URL string.
3. Health Check Endpoint:
@app.get("/health")
def health_check():
return {"status": "ok"}It is a Simple route to confirm that the API is alive and running.
4. Main Summarization Endpoint:
@app.post("/summarize_arxiv/")
async def summarize_arxiv(request: URLRequest):It will Accepts a POST request by a URL.
It will Downloads and extracts the PDF text.
It will Splits and summarizes the text in a parallel with retries.
It will Combines the results into a final technical document by Ollama.
5. PDF Download Function:
def download_pdf(url):
...
This will Checks the URL format to ensure that it’s from Arxiv or not.
It will Downloads the file and stores it as an arxiv_paper.pdf .
6. Text Extraction:
def extract_text_from_pdf(pdf_path):
...
It Uses PyMuPDF (fitz) to quickly extract the readable text from the PDF pages.
7. Text Splitting & Chunking:
splitter = RecursiveCharacterTextSplitter(...)
chunks = splitter.split_text(text)
It Uses the Langchain’s RecursiveCharacterTextSplitter to divide the text.
It will Helps in managing the Gemma’s token limits (128K context).
8. Parallel Summarization with Retry:
tasks = [summarize_chunk_with_retry(chunk, i+1, ...) for i, chunk in enumerate(chunks)]
summaries = await asyncio.gather(*tasks, return_exceptions=True)
The Chunks are processed concurrently using asyncio.
9. Ollama Summarization:
async def summarize_chunk_wrapper(chunk, chunk_id, ...):
It will Sends a structured prompt to
http://localhost:11434/api/chat.It Includes the system and user roles.
It Uses
httpx.AsyncClientwith long timeouts for stability.
10. Final Summary Generation:
final_messages = [{...}]
response = await client.post("http://localhost:11434/api/chat", json=payload)By this, All partial summaries are compiled and sent again to Gemma.
This step will creates a structured, final technical report with the following sections:
System Architecture
Implementation
Infrastructure
Performance
Optimization
11. App Entry Point:
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
It will Launches the API server on port 8000.
12. Page Configuration:
st.set_page_config(page_title="📄 AI-Powered PDF Summarizer", layout="wide")
It will Sets the page title and chooses a wide layout to give more space for displaying content Perfectly.
13. Custom Styling:
st.markdown(""" <style>...</style> """, unsafe_allow_html=True)This section of the code will applies custom CSS styling to enhance the look and feel:
Dark background with modern fonts.
Stylish input boxes and buttons.
Colored titles and headers.
Summary content styled inside clean, bordered boxes.
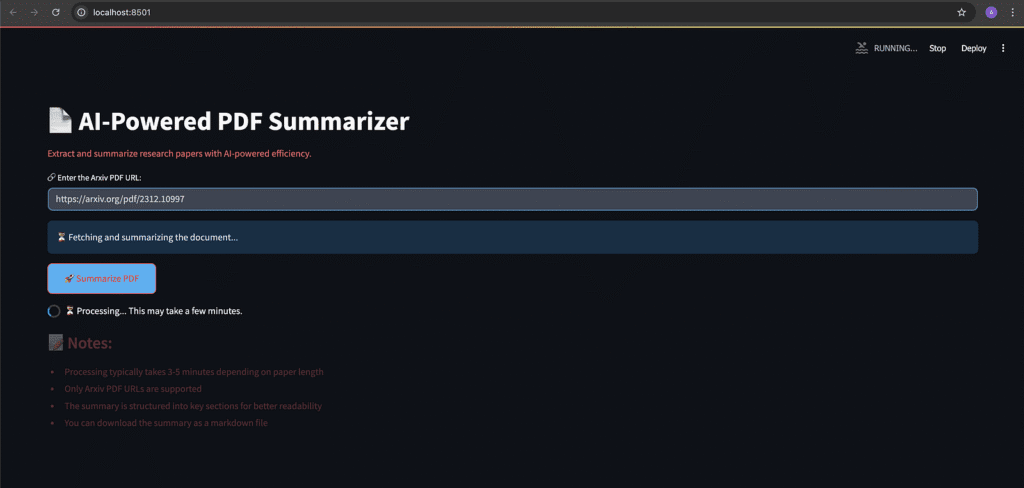
14. Title and Description:
st.title("📄 AI-Powered PDF Summarizer")
st.markdown("Extract and summarize research papers with AI-powered efficiency.")This will Sets the main header of the app.
This will Adds a short description under the title.
15. PDF URL Input:
pdf_url = st.text_input("🔗 Enter the Arxiv PDF URL:", placeholder="https://arxiv.org/pdf/2401.02385.pdf")This is the location, where the user enters the URL of an Arxiv PDF.
A placeholder will shows an example URL for guiding.
16. Status Message Placeholder:
status_placeholder = st.empty()
This will Creates an empty space on the page to later display status messages, like “Processing…”, “Success”, or “Error”.
17. Formatting Function:
def format_section(title, content):
return f"""<div class="summary-section">...</div>"""
This helper function will formats the each section of the summary (like Introduction, Results, etc.) using this defined CSS styles.
18. Summarization Logic:
if st.button("🚀 Summarize PDF"):This will triggers, when the user clicks the Summarize PDF button.
19. Notes and Instructions:
st.markdown("---")
st.markdown("""### 📝 Notes: ...""")This will Adds a horizontal line and an instructional section at the bottom to help users:
Explains supported URLs.
The Average processing time.
Notes that summary is split into readable sections.
This will Tells the users that they can download the summary.
Source Code:
main.py
import os
import logging
import requests
import fitz
import asyncio
import json
import httpx
from concurrent.futures import ThreadPoolExecutor
from fastapi import FastAPI
from pydantic import BaseModel
from langchain.text_splitter import RecursiveCharacterTextSplitter
import ollama
# Configure logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
# Initialize FastAPI
app = FastAPI()
class URLRequest(BaseModel):
url: str
@app.get("/health")
def health_check():
return {"status": "ok", "message": "FastAPI backend is running!"}
@app.post("/summarize_arxiv/")
async def summarize_arxiv(request: URLRequest):
"""Downloads an Arxiv PDF, extracts text, and summarizes it using Ollama (Gemma 3) in parallel."""
try:
url = request.url
logger.info("---------------------------------------------------------")
logger.info(f"Downloading PDF from: {url}")
pdf_path = download_pdf(url)
if not pdf_path:
return {"error": "Failed to download PDF. Check the URL."}
logger.info(f"PDF saved at: {pdf_path}")
# Extract text from the PDF
text = extract_text_from_pdf(pdf_path)
if not text:
return {"error": "No text extracted from PDF"}
logger.info(f"Extracted text length: {len(text)} characters")
logger.info("---------------------------------------------------------")
# Summarize extracted text in parallel
summary = await summarize_text_parallel(text)
logger.info("Summarization complete")
return {"summary": summary}
except Exception as e:
logger.error(f"Error processing PDF: {e}")
return {"error": "Failed to process PDF"}
def download_pdf(url):
"""Downloads a PDF from a given URL and saves it locally."""
try:
if not url.startswith("https://arxiv.org/pdf/"):
logger.error(f"Invalid URL: {url}")
return None # Prevents downloading non-Arxiv PDFs
response = requests.get(url, timeout=30) # Set timeout to prevent long waits
if response.status_code == 200 and "application/pdf" in response.headers.get("Content-Type", ""):
pdf_filename = "arxiv_paper.pdf"
with open(pdf_filename, "wb") as f:
f.write(response.content)
return pdf_filename
else:
logger.error(f"Failed to download PDF: {response.status_code} (Not a valid PDF)")
return None
except requests.exceptions.RequestException as e:
logger.error(f"Error downloading PDF: {e}")
return None
def extract_text_from_pdf(pdf_path):
"""Extracts text from a PDF file using PyMuPDF (faster than Unstructured PDFLoader)."""
try:
doc = fitz.open(pdf_path)
text = "\n".join([page.get_text("text") for page in doc])
return text
except Exception as e:
logger.error(f"Error extracting text: {e}")
return ""
async def summarize_chunk_with_retry(chunk, chunk_id, total_chunks, max_retries=2):
"""Retry mechanism wrapper for summarize_chunk_wrapper."""
retries = 0
while retries 0:
logger.info(f"🔄 Retry attempt {retries}/{max_retries} for chunk {chunk_id}/{total_chunks}")
result = await summarize_chunk_wrapper(chunk, chunk_id, total_chunks)
# If the result starts with "Error", it means there was an error but no exception was thrown
if isinstance(result, str) and result.startswith("Error"):
logger.warning(f"⚠️ Soft error on attempt {retries+1}/{max_retries+1} for chunk {chunk_id}: {result}")
retries += 1
if retries 0:
logger.info(f"✅ Successfully processed chunk {chunk_id} after {retries} retries")
return result
except Exception as e:
retries += 1
logger.error(f"❌ Exception on attempt {retries}/{max_retries+1} for chunk {chunk_id}: {str(e)}")
if retries <= max_retries:
# Exponential backoff
wait_time = 5 * (2 ** (retries - 1))
logger.info(f"⏳ Waiting {wait_time}s before retry for chunk {chunk_id}")
await asyncio.sleep(wait_time)
else:
logger.error(f"❌ All retry attempts exhausted for chunk {chunk_id}")
return f"Error processing chunk {chunk_id} after {max_retries+1} attempts: {str(e)}"
# This should never be reached, but just in case
return f"Error: Unexpected end of retry loop for chunk {chunk_id}"
async def summarize_text_parallel(text):
"""Process text in chunks optimized for Gemma 3's 128K context window with full parallelism and retry logic."""
token_estimate = len(text) // 4
logger.info(f"📝 Token Estimate: {token_estimate}")
# Use larger chunks since Gemma 3 can handle 128K tokens
chunk_size = 10000 * 4 # Approximately 32K tokens per chunk
chunk_overlap = 100 # Larger overlap to maintain context
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", ". ", " ", ""]
)
chunks = splitter.split_text(text)
logger.info("---------------------------------------------------------")
logger.info(f"📚 Split text into {len(chunks)} chunks")
logger.info("---------------------------------------------------------")
# Log chunk details
for i, chunk in enumerate(chunks, 1):
chunk_length = len(chunk)
logger.info(f"📊 Length: {chunk_length} characters ({chunk_length // 4} estimated tokens)")
logger.info("---------------------------------------------------------")
logger.info(f"🔄 Processing {len(chunks)} chunks in parallel with retry mechanism...")
# Create tasks for each chunk with retry mechanism
tasks = [summarize_chunk_with_retry(chunk, i+1, len(chunks), max_retries=2) for i, chunk in enumerate(chunks)]
# Process chunks with proper error handling at the gather level
try:
# Using return_exceptions=True to prevent one failure from canceling all tasks
summaries = await asyncio.gather(*tasks, return_exceptions=True)
# Process the results, handling any exceptions
processed_summaries = []
for i, result in enumerate(summaries):
if isinstance(result, Exception):
# An exception was returned
logger.error(f"❌ Task for chunk {i+1} returned an exception: {str(result)}")
processed_summaries.append(f"Error processing chunk {i+1}: {str(result)}")
else:
# Normal result
processed_summaries.append(result)
summaries = processed_summaries
except Exception as e:
logger.error(f"❌ Critical error in gather operation: {str(e)}")
return f"Critical error during processing: {str(e)}"
logger.info("✅ All chunks processed (with or without errors)")
# Check if we have at least some successful results
successful_summaries = [s for s in summaries if not (isinstance(s, str) and s.startswith("Error"))]
if not successful_summaries:
logger.warning("⚠️ No successful summaries were generated.")
return "No meaningful summary could be generated. All chunks failed processing."
# Combine summaries with section markers, including error messages for failed chunks
combined_chunk_summaries = "\n\n".join(f"Section {i+1}:\n{summary}" for i, summary in enumerate(summaries))
logger.info(f"📝 Combined summaries length: {len(combined_chunk_summaries)} characters")
logger.info("🔄 Generating final summary...")
# Create final summary with system message
final_messages = [
{
"role": "system",
"content": "You are a technical documentation writer. Focus ONLY on technical details, implementations, and results. DO NOT mention papers, citations, or authors."
},
{
"role": "user",
"content": f"""Create a comprehensive technical document focusing ONLY on the implementation and results.
Structure the content into these sections:
1. System Architecture
2. Technical Implementation
3. Infrastructure & Setup
4. Performance Analysis
5. Optimization Techniques
CRITICAL INSTRUCTIONS:
- Focus ONLY on technical details and implementations
- Include specific numbers, metrics, and measurements
- Explain HOW things work
- DO NOT include any citations or references
- DO NOT mention other research or related work
- Some sections may contain error messages - please ignore these and work with available information
Content to organize:
{combined_chunk_summaries}
"""
}
]
# Use async http client for the final summary with retry logic
max_retries = 2
retry_count = 0
final_response = None
while retry_count <= max_retries:
try:
# Use async http client for the final summary as well
payload = {
"model": "gemma3:27b",
"messages": final_messages,
"stream": False
}
logger.info(f"📤 Sending final summary request (attempt {retry_count+1}/{max_retries+1})")
# Make async HTTP request with increased timeout for final summary
async with httpx.AsyncClient() as client:
response = await client.post(
"http://localhost:11434/api/chat",
json=payload,
timeout=httpx.Timeout(connect=60, read=3600, write=60, pool=60) # 15-minute read timeout
)
logger.info(f"📥 Received final summary response, status code: {response.status_code}")
if response.status_code != 200:
raise Exception(f"API returned non-200 status code: {response.status_code} - {response.text}")
final_response = response.json()
break # Success, exit retry loop
except Exception as e:
retry_count += 1
logger.error(f"❌ Error generating final summary (attempt {retry_count}/{max_retries+1}): {str(e)}")
if retry_count <= max_retries:
# Exponential backoff
wait_time = 10 * (2 ** (retry_count - 1))
logger.info(f"⏳ Waiting {wait_time}s before retrying final summary generation")
await asyncio.sleep(wait_time)
else:
logger.error(f"❌ All retry attempts for final summary failed")
return "Failed to generate final summary after multiple attempts. Please check the logs for details."
if not final_response:
return "Failed to generate final summary. Please check the logs for details."
logger.info("✅ Final summary generated")
logger.info(f"📊 Final summary length: {len(final_response['message']['content'])} characters")
return final_response['message']['content']
async def summarize_chunk_wrapper(chunk, chunk_id, total_chunks):
"""Asynchronous wrapper for summarizing a single chunk using Ollama via async httpx."""
logger.info("---------------------------------------------------------")
logger.info(f"🎯 Starting processing of chunk {chunk_id}/{total_chunks}")
try:
# Add system message to better control output
messages = [
{"role": "system", "content": "Extract only technical details. No citations or references."},
{"role": "user", "content": f"Extract technical content: {chunk}"}
]
# Use httpx for truly parallel API calls
payload = {
"model": "gemma3:27b",
"messages": messages,
"stream": False
}
# Add better timeout and error handling
try:
# Make async HTTP request directly to Ollama API
async with httpx.AsyncClient(timeout=3600) as client: # Increased timeout to 10 minutes
logger.info(f"📤 Sending request for chunk {chunk_id}/{total_chunks} to Ollama API - Gemma3 ")
response = await client.post(
"http://localhost:11434/api/chat", # Default Ollama API endpoint
json=payload,
# Adding connection timeout and timeout parameters
timeout=httpx.Timeout(connect=60, read=3600, write=60, pool=60)
)
logger.info("---------------------------------------------------------")
logger.info(f"📥 Received response for chunk {chunk_id}/{total_chunks}, status code: {response.status_code}")
if response.status_code != 200:
error_msg = f"Ollama API error: {response.status_code} - {response.text}"
logger.error(error_msg)
return f"Error processing chunk {chunk_id}: API returned status code {response.status_code}"
response_data = response.json()
summary = response_data['message']['content']
logger.info(f"✅ Completed chunk {chunk_id}/{total_chunks}")
logger.info(f"📑 Summary length: {len(summary)} characters")
logger.info("---------------------------------------------------------")
return summary
except httpx.TimeoutException as te:
error_msg = f"Timeout error for chunk {chunk_id}: {str(te)}"
logger.error(error_msg)
return f"Error in chunk {chunk_id}: Request timed out after 30 minutes. Consider increasing the timeout or reducing chunk size."
except httpx.ConnectionError as ce:
error_msg = f"Connection error for chunk {chunk_id}: {str(ce)}"
logger.error(error_msg)
return f"Error in chunk {chunk_id}: Could not connect to Ollama API. Check if Ollama is running correctly."
except Exception as e:
# Capture and log the full exception details
import traceback
error_details = traceback.format_exc()
logger.error(f"❌ Error processing chunk {chunk_id}: {str(e)}")
logger.error(f"Traceback: {error_details}")
return f"Error processing chunk {chunk_id}: {str(e)}"
# Keep this function as a reference or remove it as it's been replaced by summarize_chunk_wrapper
def summarize_chunk(chunk, chunk_id):
"""Summarizes a single chunk using Ollama (Gemma 3 LLM)."""
logger.info(f"\n{'=' * 40} Processing Chunk {chunk_id} {'=' * 40}")
logger.info(f"📄 Input chunk length: {len(chunk)} characters")
prompt = f"""
You are a technical content extractor. Extract and explain ONLY the technical details from this section.
Focus on:
1. **System Architecture** – Design, component interactions, algorithms, configurations.
2. **Implementation** – Code/pseudocode, data structures, formulas (with explanations), parameter values.
3. **Experiments** – Hardware (GPUs, RAM), software versions, dataset size, training hyperparameters.
4. **Results** – Performance metrics (accuracy, latency, memory usage), comparisons.
**Rules:**
- NO citations, references, or related work.
- NO mention of authors or external papers.
- ONLY technical details, numbers, and implementations.
Text to analyze:
{chunk}
"""
try:
logger.info(f"🤖 Sending chunk {chunk_id} to Ollama...")
response = ollama.chat(model="gemma3:27b", messages=[{"role": "user", "content": prompt}])
summary = response['message']['content']
logger.info(f"✅ Successfully processed chunk {chunk_id}")
logger.info(f"📊 Summary length: {len(summary)} characters")
print(summary)
return summary
except Exception as e:
logger.error(f"❌ Error summarizing chunk {chunk_id}: {e}")
return f"Error summarizing chunk {chunk_id}"
if __name__ == "__main__":
import uvicorn
logger.info("Starting FastAPI server on http://localhost:8000")
uvicorn.run(app, host="0.0.0.0", port=8000, log_level="info")
frontend.py
import streamlit as st
import requests
import time
# Streamlit UI setup
st.set_page_config(page_title="📄 AI-Powered PDF Summarizer", layout="wide")
# Apply custom styling for a sleek professional UI
st.markdown("""
body {
background-color: #282c34; /* Darker background */
color: #abb2bf; /* Lighter, less harsh text */
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif; /* Modern font */
}
.stTextInput>div>div>input {
font-size: 16px;
padding: 12px;
border-radius: 8px;
border: 1px solid #61afef; /* Softer blue */
background-color: #3e4451; /* Darker input background */
color: #d1d5db; /* Light gray input text */
}
.stButton>button {
background-color: #61afef; /* Softer blue button */
color: #ffffff;
font-size: 18px;
font-weight: bold;
padding: 12px 28px;
border-radius: 8px;
transition: all 0.3s;
}
.stButton>button:hover {
background-color: #569cd6; /* Slightly darker on hover */
transform: translateY(-2px);
}
.stMarkdown, .stSubheader {
color: #e06c75; /* Soft red for headers */
font-weight: bold;
}
.summary-section {
background-color: #3e4451;
padding: 20px;
border-radius: 10px;
margin-bottom: 20px;
border-left: 5px solid #61afef;
}
.section-title {
color: #61afef;
font-size: 24px;
margin-bottom: 15px;
}
.section-content {
color: #d1d5db;
font-size: 16px;
line-height: 1.6;
}
""", unsafe_allow_html=True)
# Professional header
st.title("📄 AI-Powered PDF Summarizer")
st.markdown("Extract and summarize research papers with AI-powered efficiency.")
# Input for PDF URL
pdf_url = st.text_input("🔗 Enter the Arxiv PDF URL:",
placeholder="https://arxiv.org/pdf/2401.02385.pdf")
# Placeholder for status messages
status_placeholder = st.empty()
def format_section(title, content):
"""Format a section of the summary with consistent styling"""
return f"""
<div class="summary-section">
<div class="section-title">{title}</div>
<div class="section-content">{content}</div>
</div>
"""
# Add a spinner and professional feedback system
if st.button("🚀 Summarize PDF"):
if pdf_url:
with st.spinner("⏳ Processing... This may take a few minutes."):
status_placeholder.info("⏳ Fetching and summarizing the document...")
try:
response = requests.post(
"http://localhost:8000/summarize_arxiv/",
json={"url": pdf_url},
timeout=3600
)
if response.status_code == 200:
data = response.json()
if "error" in data:
status_placeholder.error(f"❌ {data['error']}")
else:
summary = data.get("summary", "No summary generated.")
status_placeholder.success("✅ Summary Ready!")
# Split the summary into sections and display them
sections = summary.split("#")[1:] # Skip empty first split
for section in sections:
if section.strip():
# Split section into title and content
parts = section.split("\n", 1)
if len(parts) == 2:
title, content = parts
st.markdown(
format_section(title.strip(), content.strip()),
unsafe_allow_html=True
)
# Add download button for the summary
st.download_button(
"⬇️ Download Summary",
summary,
file_name="paper_summary.md",
mime="text/markdown"
)
else:
status_placeholder.error("❌ Failed to process the PDF. Please check the URL and try again.")
except requests.exceptions.Timeout:
status_placeholder.error("⚠️ Request timed out. Please try again later.")
except Exception as e:
status_placeholder.error(f"⚠️ An error occurred: {str(e)}")
else:
status_placeholder.warning("⚠️ Please enter a valid Arxiv PDF URL.")
# Add helpful instructions at the bottom
st.markdown("---")
st.markdown("""
### 📝 Notes:
- Processing typically takes 3-5 minutes depending on paper length
- Only Arxiv PDF URLs are supported
- The summary is structured into key sections for better readability
- You can download the summary as a markdown file
""")
Output:
Get Huge Discounts

More Python Projects
