
AI Based Career Path Recommender Using Python

Introduction:
One of the most significant and frequently perplexing decisions in a person’s life is selecting the appropriate career path. Students and young professionals frequently struggle to find a path that aligns with their skills, interests, and goals due to the abundance of options and the quickly evolving job markets. The AI-Based Career Path Recommender project uses machine learning and Python to address this issue.
Purpose of This Project:
This project’s goal is to assist users in choosing the best career options based on their preferences, interests, personality traits, and academic background. It removes the element of guesswork and substitutes it with wise recommendations. Students selecting their majors, recent graduates seeking employment, and anyone thinking about changing careers can all benefit from it.
Key Features:
- AI-driven, tailored career recommendations.
- The user interface is easy to use and captivating.
- For enjoyable interaction, gamified quizzes can be included.
- Giving feedback is an option to enhance future outcomes.
- Scalable to incorporate LinkedIn integration or resume analysis.
This project is unique because it integrates data science, psychology, and career counseling into a single intelligent tool that serves as a potent roadmap for future planning.
Required Modules Or Packages:
- Streamlit: It is used to create an interactive web apps easily using Python.
- Pandas: It is used to handle data and manipulation in tabular form.
- CountVectorizer: It converts the text data into numerical format for machine learning.
- RandomForestClassifier: It is a model of machine learning which is used for classification tasks.
- LabelEncoder: It converts the categorical labels into numeric form.
- cosine_similarity: It measures that how are similar two vectors (e.g., texts) .
- NumPy: It is used for Operating numericals and to handle arrays.
To install these Packages, use the following command:
1. StreamLit:
pip install streamlit
2. Pandas:
pip install pandas
3. Scikit-Learn:
pip install scikit-learn
4. Numpy:
pip install numpy
How To Run The Code:
Method 1:
Step 1 . First , You Download and Install Visual Studio Code or VS Code In your PC or Laptop by VS Code Official Website .
Step 2 . Now Open CMD As Administrator and install the above packages using Pip .
Step 3 . Now Open Visual Studio Code .
Step 4. Now Make The file named as main.py or career.py .
Step 5 . Now Copy And Paste The Code from the Link Given Below ⬇️
Step 6 . After pasting The Code , Save This & Click On Run Button .
Step 7 . Now You will See The Output .
Method 2:
Step 1 . First , You Download and Install Visual Studio Code or VS Code In your PC or Laptop by VS Code Official Website .
Step 2 . Now Open CMD As Administrator and install the above packages using Pip .
Step 3 . Now Open the Github link , which is provided below.
Step 4. Now download the ZIP file of the code.
Step 5 . Now Extract the ZIP file and Open in VS Code.
Step 6 . Now go to the main file and click on run button.
Step 7 . Now You will See The Output .
Code Explanation:
This Python code is used to Create an AI Based Career Path Recommender . Ensures that You Have Downloaded the modules given above .
1. Importing Required Libraries:
import streamlit as st
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
- Streamlit: It is used to create an interactive web apps easily using Python.
- Pandas: It is used to handle data and manipulation in tabular form.
- CountVectorizer: It converts the text data into numerical format for machine learning.
- RandomForestClassifier: It is a model of machine learning which is used for classification tasks.
- LabelEncoder: It converts the categorical labels into numeric form.
- cosine_similarity: It measures that how are similar two vectors (e.g., texts) .
- NumPy: It is used for Operating numericals and to handle arrays.
2. Simulated Dataset:
data = [ {...}, {...}, ... ]
df = pd.DataFrame(data)This section of the code defines a small sample dataset of career options. Each entry has a fields like: job_title, skills, education, interests, experience, and description.
The dataset is stored in a Pandas DataFrame which is called as df, which is used to train the ML model and generate recommendations.
3. Feature Engineering:
def combine_text_features(row):
return f"{row['skills']} {row['education']} {row['interests']} {row['experience']}"
df['combined_features'] = df.apply(combine_text_features, axis=1)
This function will combines all the key textual information into one string per job. It’s important because it can prepares the data for text vectorization.
4. Vectorization and Label Encoding:
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['combined_features'])
le = LabelEncoder()
y = le.fit_transform(df[‘job_title’])
CountVectorizer: It is used to transforms text into numeric features.
LabelEncoder: It converts the job titles into numerical labels for classification.
5. Model Training:
model = RandomForestClassifier(random_state=42)
model.fit(X, y)
Random Forest Classifier: It is trained to learn the relationship between the text features and job titles.
This Block of the code allows the model to predict the best-fitting job titles based on the user input.
6. Streamlit UI:
skills_input = st.text_input(...)
education_input = st.selectbox(...)
interests_input = st.text_input(...)
experience_input = st.selectbox(...)
These widgets are important, through which user can input their profile information.
7. Prediction and Similarity Matching:
user_vector = vectorizer.transform([user_features])
pred_probs = model.predict_proba(user_vector)[0]
These user inputs is transformed and passed into the ML model to get probabilities for each job.
To improve the accuracy, cosine similarity is calculated:
user_skills_vec = text_to_vector(skills_input.lower())
career_skills_vec = vectorizer.transform(descriptions)
similarities = cosine_similarity(user_skills_vec, career_skills_vec)[0]
This block of the code measures that how closely the user’s skills match the job’s required skills.
8. Combining Scores and Displaying Results:
combined_scores = 0.7 * pred_probs + 0.3 * similarities
top3_idx = combined_scores.argsort()[::-1][:3]
It Combines the ML model probability and similarity score.
It Sort out and selects the top 3 recommended careers to display.
The Streamlit will then presents job descriptions, required skills, and other info.
Source Code:
import streamlit as st
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# ---------------------------------
# 1. Simulated dataset of career profiles
# Each career has title, required skills, education, interests, experience level, description
data = [
{
"job_title": "Data Scientist",
"skills": "python, machine learning, statistics, data visualization",
"education": "bachelor",
"interests": "data, analytics, research",
"experience": "mid",
"description": "Analyzes data to extract insights and build predictive models."
},
{
"job_title": "Software Engineer",
"skills": "java, c++, algorithms, problem solving",
"education": "bachelor",
"interests": "coding, development, problem solving",
"experience": "junior",
"description": "Designs and develops software applications and systems."
},
{
"job_title": "Graphic Designer",
"skills": "photoshop, creativity, adobe illustrator, visual design",
"education": "associate",
"interests": "art, creativity, media",
"experience": "entry",
"description": "Creates visual concepts to communicate ideas."
},
{
"job_title": "Project Manager",
"skills": "leadership, communication, scheduling, budgeting",
"education": "bachelor",
"interests": "management, organization, planning",
"experience": "senior",
"description": "Oversees projects to ensure timely delivery within budget."
},
{
"job_title": "Marketing Specialist",
"skills": "seo, content creation, social media, communication",
"education": "bachelor",
"interests": "marketing, branding, communication",
"experience": "mid",
"description": "Develops strategies to promote products and brands."
},
{
"job_title": "Cybersecurity Analyst",
"skills": "network security, python, risk assessment, cryptography",
"education": "bachelor",
"interests": "security, technology, risk management",
"experience": "mid",
"description": "Protects an organization's computer systems and networks."
},
{
"job_title": "Mechanical Engineer",
"skills": "cad, thermodynamics, mechanics, problem solving",
"education": "bachelor",
"interests": "engineering, mechanics, design",
"experience": "mid",
"description": "Designs and tests mechanical devices and systems."
},
{
"job_title": "Financial Analyst",
"skills": "excel, finance, accounting, data analysis",
"education": "bachelor",
"interests": "finance, economics, data",
"experience": "junior",
"description": "Provides investment and financial recommendations."
},
{
"job_title": "Teacher",
"skills": "communication, patience, subject knowledge, mentoring",
"education": "bachelor",
"interests": "teaching, education, helping others",
"experience": "mid",
"description": "Educates and supports students in learning."
},
{
"job_title": "UX Designer",
"skills": "wireframing, user research, creativity, prototyping",
"education": "bachelor",
"interests": "design, user experience, psychology",
"experience": "mid",
"description": "Improves user satisfaction with products by enhancing usability."
},
]
df = pd.DataFrame(data)
# ---------------------------------
# 2. Data preparation
# Combine all textual information into a single string feature
def combine_text_features(row):
return f"{row['skills']} {row['education']} {row['interests']} {row['experience']}"
df['combined_features'] = df.apply(combine_text_features, axis=1)
# Vectorize the combined features using CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['combined_features'])
# Encode job titles as labels for classification
le = LabelEncoder()
y = le.fit_transform(df['job_title'])
# ---------------------------------
# Model training
# Using a Random Forest Classifier to learn from combined textual features
model = RandomForestClassifier(random_state=42)
model.fit(X, y)
# ---------------------------------
# Streamlit UI
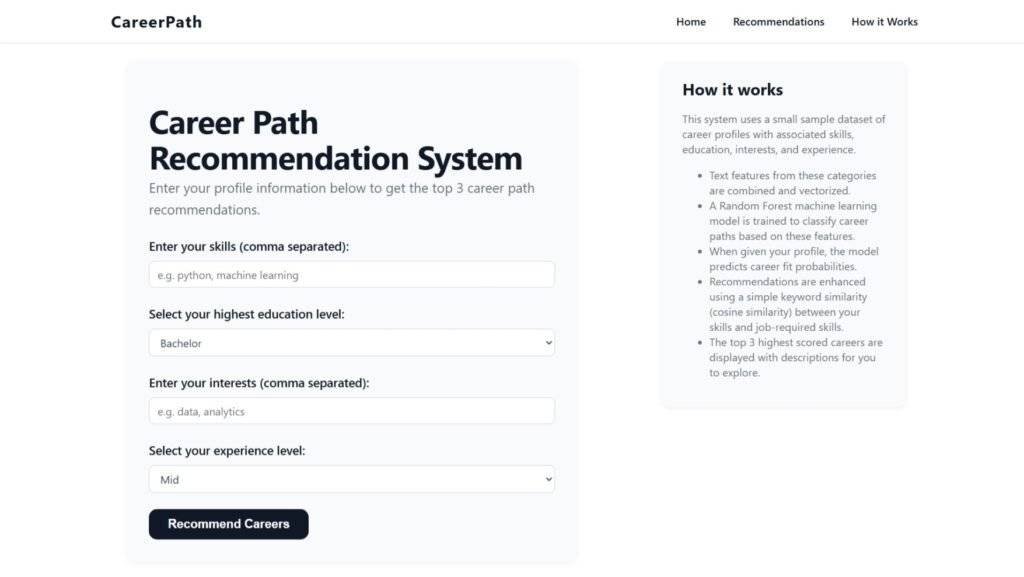
st.title("Career Path Recommendation System")
st.markdown("""
Enter your profile information below to get the top 3 career path recommendations.
""")
# User inputs
skills_input = st.text_input("Enter your skills (comma separated):", "")
education_input = st.selectbox("Select your highest education level:",
['highschool', 'associate', 'bachelor', 'master', 'phd'])
interests_input = st.text_input("Enter your interests (comma separated):", "")
experience_input = st.selectbox("Select your experience level:", ['entry', 'junior', 'mid', 'senior'])
# When user clicks the button, predict career recommendations
if st.button("Recommend Careers"):
# Prepare user input: combine all fields same way as dataset
user_features = f"{skills_input} {education_input} {interests_input} {experience_input}"
user_vector = vectorizer.transform([user_features])
# Predict probabilities for each class (career)
pred_probs = model.predict_proba(user_vector)[0]
# Add NLP keyword matching similarity to enhance recommendations
# For each career, calculate cosine similarity between user skills and job skills
def text_to_vector(text):
# Simple vectorization using CountVectorizer limited to skill vocabulary only
skill_vectorizer = CountVectorizer(vocabulary=vectorizer.vocabulary_)
return skill_vectorizer.transform([text])
user_skills_vec = text_to_vector(skills_input.lower())
descriptions = df['skills'].str.lower().values
career_skills_vec = vectorizer.transform(descriptions)
similarities = cosine_similarity(user_skills_vec, career_skills_vec)[0]
# Combine model prediction probability and similarity score by weighted sum
combined_scores = 0.7 * pred_probs + 0.3 * similarities
# Get indices of top 3 recommended careers
top3_idx = combined_scores.argsort()[::-1][:3]
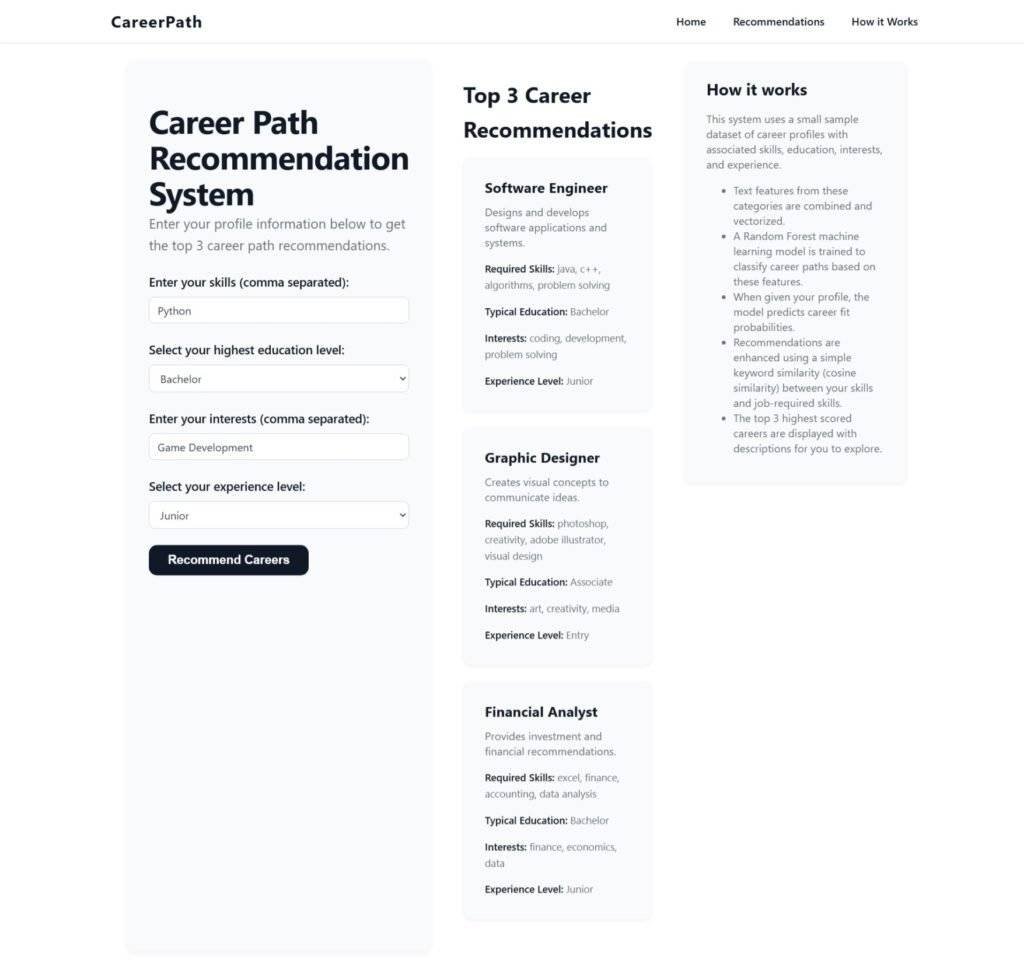
st.subheader("Top 3 Career Recommendations")
for idx in top3_idx:
st.markdown(f"### {df.iloc[idx]['job_title']}")
st.write(df.iloc[idx]['description'])
st.markdown(f"**Required Skills:** {df.iloc[idx]['skills']}")
st.markdown(f"**Typical Education:** {df.iloc[idx]['education'].capitalize()}")
st.markdown(f"**Interests:** {df.iloc[idx]['interests']}")
st.markdown(f"**Experience Level:** {df.iloc[idx]['experience'].capitalize()}")
st.markdown("---")
# ---------------------------------
# Explanation of process in sidebar
st.sidebar.title("How it works")
st.sidebar.info("""
This system uses a small sample dataset of career profiles with associated skills, education, interests, and experience.
- Text features from these categories are combined and vectorized.
- A Random Forest machine learning model is trained to classify career paths based on these features.
- When given your profile, the model predicts career fit probabilities.
- Recommendations are enhanced using a simple keyword similarity (cosine similarity) between your skills and job-required skills.
- The top 3 highest scored careers are displayed with descriptions for you to explore.
""")
Output:
Get Huge Discounts

More Python Projects
