
OCR Scanner Text from Image in python
introduction
Optical Character Recognition (OCR) is a powerful technology that enables computers to recognize and extract text from images, scanned documents, or handwritten notes. This technology is widely used in digitizing printed or handwritten documents, automating data entry processes, reading license plates, assisting the visually impaired, and even translating text from photographs.
In this project, we build an interactive OCR Scanner Text from Image in python with a Graphical User Interface (GUI) using Python’s built-in Tkinter library. The core of the OCR functionality is powered by Tesseract OCR, an open-source OCR engine developed by Google. We use the pytesseract Python wrapper to interface with the Tesseract engine seamlessly.
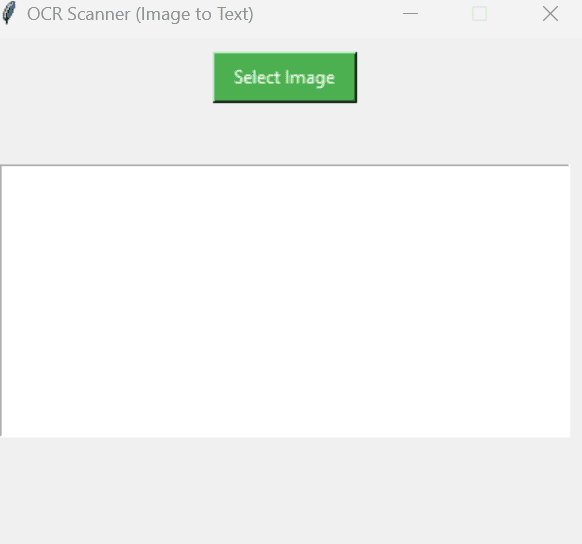
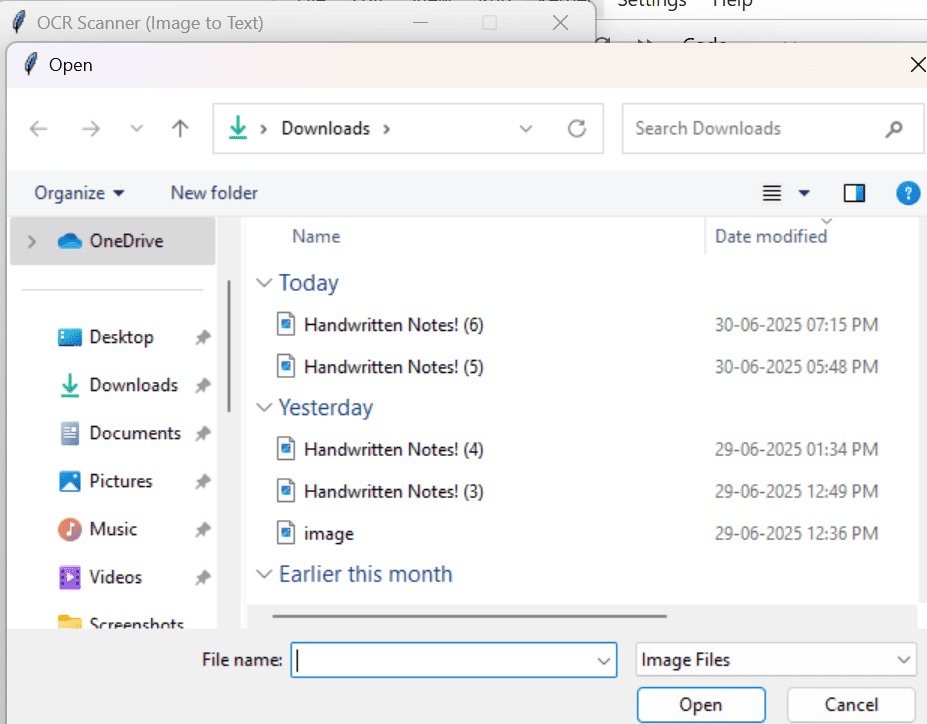
The GUI allows users to select an image from their computer using a file dialog, displays the selected image within the window, and automatically extracts and displays the text content in a scrollable textbox. This makes the tool highly user-friendly and interactive, especially for non-technical users who prefer graphical tools over command-line scripts.
Unlike console applications or web-based tools that require complex setups, this GUI-based OCR tool is lightweight, runs locally, and doesn’t require an internet connection once dependencies are installed. It’s particularly useful for educators, researchers, students, and professionals who need to extract text from screenshots, scanned notes, book pages, or forms.
Project Objectives:
To create a simple, intuitive GUI application for OCR.
To allow users to select and preview images easily.
To extract text content from the image using Tesseract OCR.
To display extracted text in a readable, editable textbox.
Technologies Used:
| Library | Purpose |
|---|---|
Tkinter | GUI development (native Python library) |
Pillow (PIL) | Handling and resizing image files |
pytesseract | Python wrapper for Tesseract OCR engine |
Tesseract OCR | Actual OCR engine for extracting text |
Key Features:
Image selection via file dialog
Image preview inside the app window
Real-time text extraction using OCR
Editable text output in a scrollable textbox
Error handling for invalid or unreadable images
Target Audience:
Students and researchers who digitize handwritten or printed notes.
Developers learning GUI and OCR integration in Python.
Office professionals needing quick text extraction tools.
Anyone looking for a desktop-based image-to-text converter.
Learning Outcomes:
How to build GUI applications using
TkinterHow to use
pytesseractfor text recognition from imagesHow to integrate image selection, display, and result output in a GUI
Understanding the basics of OCR and its use cases
steps to create OCR scanner text from image in python
Step 1: Install Required Libraries
You need to install the following Python libraries if they are not already installed:
!pip install pytesseract pillow
Also, make sure Tesseract OCR engine is installed on your system:
Windows: Download and install from https://github.com/tesseract-ocr/tesseract
Linux/macOS: Install using
sudo apt install tesseract-ocr
Optionally, set the Tesseract executable path in your code:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
Step 2: Import Required Modules
Import the necessary Python libraries:
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
import pytesseract
Step 3: Define the Image Selection and OCR Function
Create a function to select an image, display it, and extract text using pytesseract:
def select_image():
filepath = filedialog.askopenfilename(filetypes=[("Image Files", "*.png *.jpg *.jpeg *.bmp")])
if filepath:
img = Image.open(filepath)
img.thumbnail((300, 300))
img_tk = ImageTk.PhotoImage(img)
panel.config(image=img_tk)
panel.image = img_tk
result.delete("1.0", tk.END)
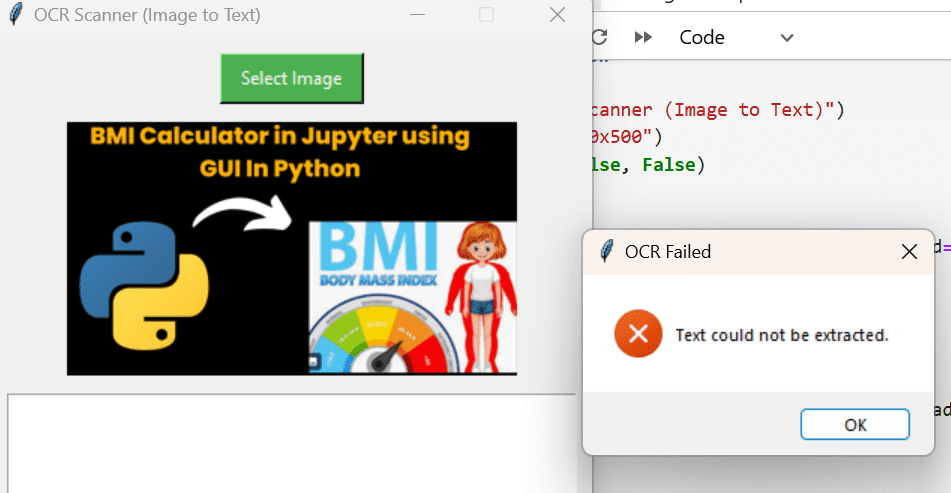
try:
text = pytesseract.image_to_string(img)
result.insert(tk.END, text)
except:
messagebox.showerror("OCR Failed", "Text could not be extracted.")
Step 4: Create the Main GUI Window
Set up the root window for your application:
root = tk.Tk()
root.title("OCR Scanner (Image to Text)")
root.geometry("400x500")
root.resizable(False, False)
Step 5: Add GUI Widgets
Add a button to trigger the image selection, a label to display the image, and a text box to show the extracted text:
btn = tk.Button(root, text="Select Image", command=select_image, bg="#4CAF50", fg="white", padx=10, pady=5)
btn.pack(pady=10)
panel = tk.Label(root)
panel.pack()
result = tk.Text(root, height=10, wrap=tk.WORD, padx=10, pady=10)
result.pack(pady=10, padx=10, fill=tk.BOTH)
Step 6: Run the Application
Start the Tkinter event loop to make the GUI responsive:
root.mainloop()
code explanation
This Python script builds a Graphical User Interface (GUI) that:
Allows the user to select an image file (JPG, PNG, etc.)
Uses Tesseract OCR (via
pytesseract) to extract text from the imageDisplays the extracted text inside the GUI
1. Install the Required Package
!pip install pytesseract
Installs
pytesseract, the Python wrapper for Google’s Tesseract OCR engine.This only needs to be run once (in Jupyter).
2. Import Required Libraries
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
import pytesseract
tkinteris used to build the GUI.filedialoglets users select files from their system.messageboxshows pop-up error alerts.PIL.Imageopens image files.ImageTkconverts PIL images to a Tkinter-compatible format.pytesseractperforms Optical Character Recognition on images.
3. (Optional) Link Tesseract Path
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
On Windows, Tesseract needs to be manually installed.
This line tells
pytesseractwhere to findtesseract.exe.
4. Function to Select Image and Extract Text
def select_image():
filepath = filedialog.askopenfilename(filetypes=[("Image Files", "*.png *.jpg *.jpeg *.bmp")])
Opens a dialog to select image files only.
if filepath:
img = Image.open(filepath) # Open the selected image
img.thumbnail((300, 300)) # Resize to fit GUI
img_tk = ImageTk.PhotoImage(img) # Convert to Tkinter image format
panel.config(image=img_tk) # Display image in label
panel.image = img_tk # Prevent image from being garbage-collected
result.delete("1.0", tk.END) # Clear previous text
try:
text = pytesseract.image_to_string(img) # Perform OCR
result.insert(tk.END, text) # Show text in text box
except:
messagebox.showerror("OCR Failed", "Text could not be extracted.")
If OCR fails (e.g., blurry image or corrupted file), show an error message.
5. Create GUI Main Window
root = tk.Tk()
root.title("OCR Scanner (Image to Text)")
root.geometry("400x500")
root.resizable(False, False)
Initializes the main window.
Sets window title, fixed size (400×500 pixels), and disables resizing.
6. Add GUI Components
btn = tk.Button(root, text="Select Image", command=select_image, bg="#4CAF50", fg="white", padx=10, pady=5)
btn.pack(pady=10)
Button to trigger file selection.
Styled with green background (
#4CAF50) and padding.
panel = tk.Label(root)
panel.pack()
Empty label to display the selected image.
result = tk.Text(root, height=10, wrap=tk.WORD, padx=10, pady=10)
result.pack(pady=10, padx=10, fill=tk.BOTH)
A multi-line textbox to show the extracted text.
Supports word-wrapping and fills available space.
7. Run the App
root.mainloop()
Starts the GUI event loop.
Keeps the window running and responsive until closed.
source code
# First, install the required package
!pip install pytesseract
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
import pytesseract
# (Optional) Windows path for tesseract executable
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def select_image():
filepath = filedialog.askopenfilename(filetypes=[("Image Files", "*.png *.jpg *.jpeg *.bmp")])
if filepath:
img = Image.open(filepath)
img.thumbnail((300, 300))
img_tk = ImageTk.PhotoImage(img)
panel.config(image=img_tk)
panel.image = img_tk # Keep reference
result.delete("1.0", tk.END)
try:
text = pytesseract.image_to_string(img)
result.insert(tk.END, text)
except:
messagebox.showerror("OCR Failed", "Text could not be extracted.")
# Create GUI Window
root = tk.Tk()
root.title("OCR Scanner (Image to Text)")
root.geometry("400x500")
root.resizable(False, False)
# GUI Components
btn = tk.Button(root, text="Select Image", command=select_image, bg="#4CAF50", fg="white", padx=10, pady=5)
btn.pack(pady=10)
panel = tk.Label(root)
panel.pack()
result = tk.Text(root, height=10, wrap=tk.WORD, padx=10, pady=10)
result.pack(pady=10, padx=10, fill=tk.BOTH)
root.mainloop()
output
Get Huge Discounts
