resume screener in python using python

introduction
The hiring process often begins with reviewing numerous resumes to filter out the most suitable candidates for a position. This manual screening is not only time-consuming but also prone to human error or bias. To simplify this process, we propose a basic Resume Screener in python application developed using Python. The primary objective is to automate the initial filtering by identifying whether a candidate possesses the essential skills required for the job.
Objective
The goal of the Resume Screener is to:
Automatically read and analyze resume text.
Identify if required job-specific skills are present.
Provide a selection decision (SELECTED / NOT SELECTED) based on the skill match.
Offer a user-friendly interface (GUI using Tkinter or text-based for online compilers).
How It Works
The Resume Screener follows a simple logic:
A set of required skills is predefined (e.g., Python, SQL, Machine Learning, etc.).
The resume is either uploaded via GUI (text file) or entered as plain text in a console.
The program extracts all text, converts it to lowercase, and searches for the required skills.
A skill match score is calculated by comparing found skills with the required ones.
Based on the number of matches, the resume is either selected or rejected.
User Interface Options
Tkinter GUI: Offers a button to upload
.txtresumes and displays results visually.Console version: Suitable for online Python compilers or basic testing—takes resume text as input directly in the code.
Example Use Case
A company is hiring for a Data Analyst role and requires candidates skilled in:
Python
SQL
Machine Learning
Data Analysis
Pandas
Communication
Benefits
Saves time in shortlisting candidates.
Reduces manual error.
Can be expanded to work with PDF files, multiple resumes, or integrated into larger HR systems.
Future Enhancements
Add support for PDF/Word resume files using
PyPDF2,docx, or OCR.Extract name, email, and contact info automatically.
Rank candidates based on number of matching skills.
Build a web-based version using Flask or Django.
Use NLP libraries like
spaCyorNLTKfor better parsing.
steps to create resume screener in python
Step 1: Define Project Objective
Decide what your Resume Screener in python should do — for example:
Upload a resume file
Compare resume content with required skills
Decide whether to select or reject the candidate
Step 2: List Required Skills
Create a list or set of key skills you want to match in resumes, such as:
Python, SQL, Machine Learning, Data Analysis, etc.
Step 3: Choose the Interface
Decide between two options:
GUI version (with Tkinter) for interactive buttons and pop-ups
Console version for text-based interaction (ideal for online compilers)
Step 4: Get Resume Input
For GUI: Use a file dialog to select a
.txtresume fileFor Console: Let the user paste or type resume content manually
Step 5: Extract and Process Resume Content
Read the content of the resume
Convert everything to lowercase (to ignore case sensitivity)
Check which required skills are mentioned
Step 6: Compare Skills
Count how many required skills are found in the resume
Compare the number of matched skills with the total skills needed
Step 7: Display Result
If the number of matched skills is more than a threshold (e.g., 50%), show “SELECTED”
Otherwise, show “NOT SELECTED”
Step 8: Test With Sample Resumes
Try the program with different resumes (text format) to verify if it correctly identifies skills and gives the expected result.
Step 9: Improve and Customize
Add support for PDF or Word documents
Extract names, emails, and contact details
Display more detailed reports or export the result
code explanation
Tools & Libraries Used
Pandas, NumPy: Data handling
Matplotlib, Seaborn: Data visualization
NLP: NLTK, Regex, Stopwords
WordCloud: Visualizing important keywords
TF-IDF Vectorizer: Text feature extraction
KNeighborsClassifier with OneVsRestClassifier: Multi-class classification
Dataset
UpdatedResumeDataSet.csv: Contains two main columns:Category: Job field/category (e.g., Data Science, HR)Resume: Raw resume text
Step 1: Load and Inspect the Dataset
Read the CSV file using
pandas.Preview data and check unique categories with
.value_counts()and.unique().
Step 2: Data Visualization
Use
seabornto show a bar chart of resume counts per category.Use
matplotlib.pie()to show a pie chart of category distribution.
Step 3: Text Preprocessing with Regex
Clean the resume text using regex:
Remove URLs, mentions, hashtags, punctuation, emojis, and extra whitespaces.
Store the cleaned version in a new column
cleaned_resume.
Step 4: Word Cloud & Frequency Analysis
Tokenize text using
nltk.Remove stopwords and punctuation.
Use
FreqDistto find most common words.Visualize with
WordCloudandmatplotlib.
Step 5: Label Encoding
Convert job categories (text) into numbers using
LabelEncoder.
Step 6: Feature Extraction (TF-IDF)
Use
TfidfVectorizerto convert resume text into numeric vectors.Parameters:
stop_words='english'max_features=1500(top 1500 most relevant words)
Step 7: Model Training
Split dataset into training and test sets (80:20).
Use
KNeighborsClassifierinsideOneVsRestClassifierto handle multi-label classification.Train the model on the TF-IDF vectors.
Step 8: Evaluation
Evaluate the model using:
Accuracy on training and test sets
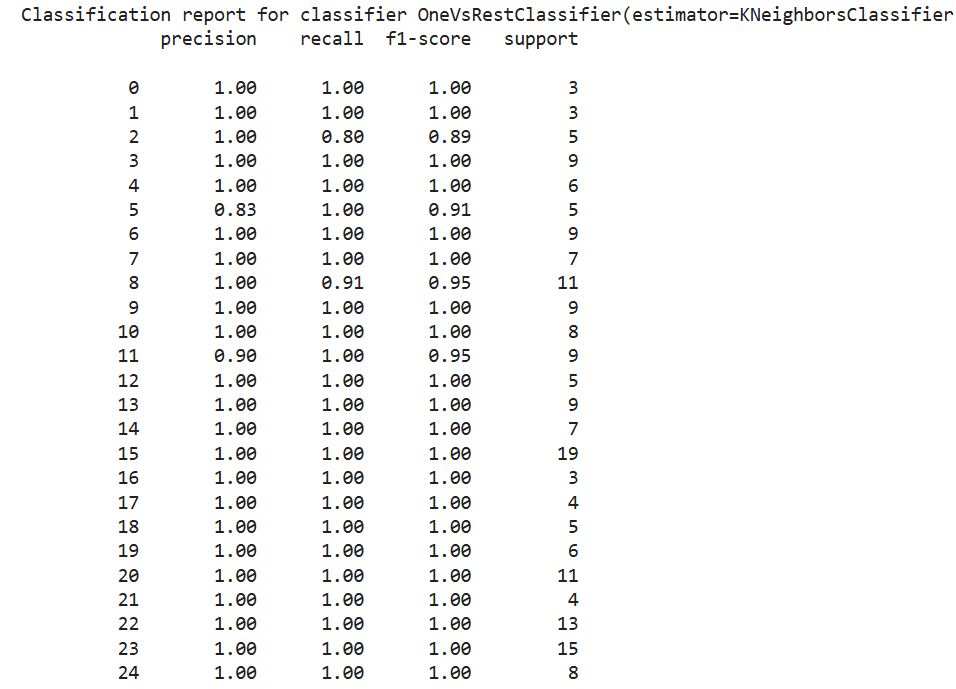
Classification report: Precision, recall, F1-score per category
Your final model achieves 99% accuracy on both training and test sets — excellent performance!
Interpretation of Results
Each resume is successfully classified into one of 25 job categories.
The model is well-generalized with high recall and precision across all categories.
source code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import re
warnings.filterwarnings('ignore')
from sklearn.naive_bayes import MultinomialNB
from sklearn.multiclass import OneVsRestClassifier
from sklearn import metrics
from sklearn.metrics import accuracy_score
from pandas.plotting import scatter_matrix
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metricsresumeDataSet = pd.read_csv('UpdatedResumeDataSet.csv' ,encoding='utf-8')
resumeDataSet['cleaned_resume'] = ''
resumeDataSet.head()
output


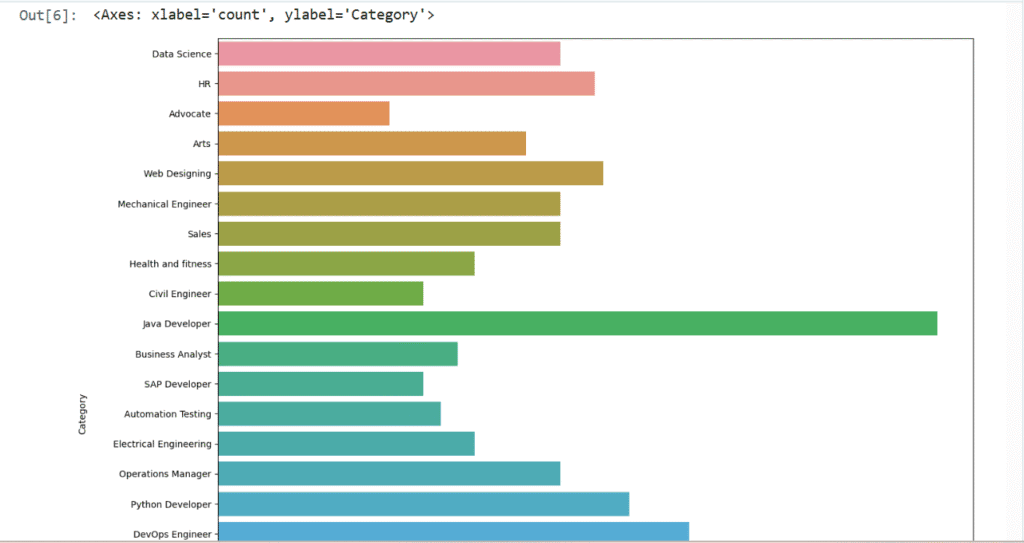
print ("Displaying the distinct categories of resume and the number of records belonging to each category -")
print (resumeDataSet['Category'].value_counts())
plt.figure(figsize=(15,15))
plt.xticks(rotation=90)
sns.countplot(y="Category", data=resumeDataSet)
from matplotlib.gridspec import GridSpec
targetCounts = resumeDataSet['Category'].value_counts()
targetLabels = resumeDataSet['Category'].unique()
# Make square figures and axes
plt.figure(1, figsize=(25,25))
the_grid = GridSpec(2, 2)
cmap = plt.get_cmap('coolwarm')
colors = [cmap(i) for i in np.linspace(0, 1, 3)]
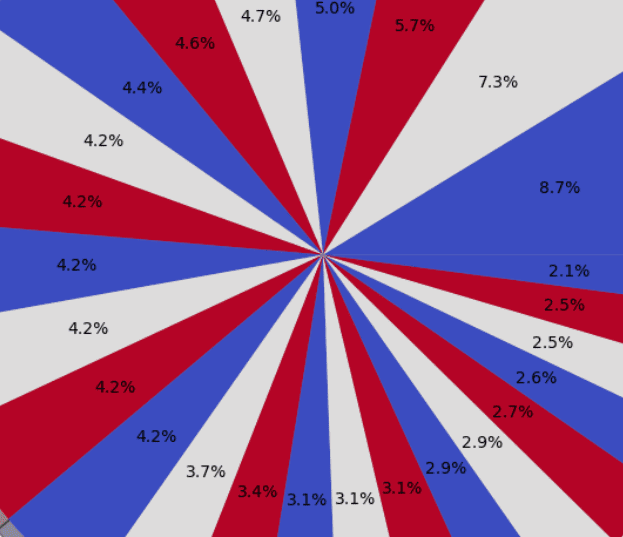
plt.subplot(the_grid[0, 1], aspect=1, title='CATEGORY DISTRIBUTION')
source_pie = plt.pie(targetCounts, labels=targetLabels, autopct='%1.1f%%', shadow=True, colors=colors)
plt.show()
def cleanResume(resumeText):
resumeText = re.sub('http\S+\s*', ' ', resumeText) # remove URLs
resumeText = re.sub('RT|cc', ' ', resumeText) # remove RT and cc
resumeText = re.sub('#\S+', '', resumeText) # remove hashtags
resumeText = re.sub('@\S+', ' ', resumeText) # remove mentions
resumeText = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;?@[\]^_`{|}~"""), ' ', resumeText) # remove punctuations
resumeText = re.sub(r'[^\x00-\x7f]',r' ', resumeText)
resumeText = re.sub('\s+', ' ', resumeText) # remove extra whitespace
return resumeText
resumeDataSet['cleaned_resume'] = resumeDataSet.Resume.apply(lambda x: cleanResume(x))import nltk
from nltk.corpus import stopwords
import string
from wordcloud import WordCloud
oneSetOfStopWords = set(stopwords.words('english')+['``',"''"])
totalWords =[]
Sentences = resumeDataSet['Resume'].values
cleanedSentences = ""
for i in range(0,160):
cleanedText = cleanResume(Sentences[i])
cleanedSentences += cleanedText
requiredWords = nltk.word_tokenize(cleanedText)
for word in requiredWords:
if word not in oneSetOfStopWords and word not in string.punctuation:
totalWords.append(word)
wordfreqdist = nltk.FreqDist(totalWords)
mostcommon = wordfreqdist.most_common(50)
print(mostcommon)
wc = WordCloud().generate(cleanedSentences)
plt.figure(figsize=(15,15))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
clf = OneVsRestClassifier(KNeighborsClassifier())
clf.fit(X_train, y_train)
prediction = clf.predict(X_test)
print('Accuracy of KNeighbors Classifier on training set: {:.2f}'.format(clf.score(X_train, y_train)))
print('Accuracy of KNeighbors Classifier on test set: {:.2f}'.format(clf.score(X_test, y_test)))
print("\n Classification report for classifier %s:\n%s\n" % (clf, metrics.classification_report(y_test, prediction)))
Get Huge Discounts

More java Pojects
Get Discount on Top EdTech Compnies